

9,353 reads
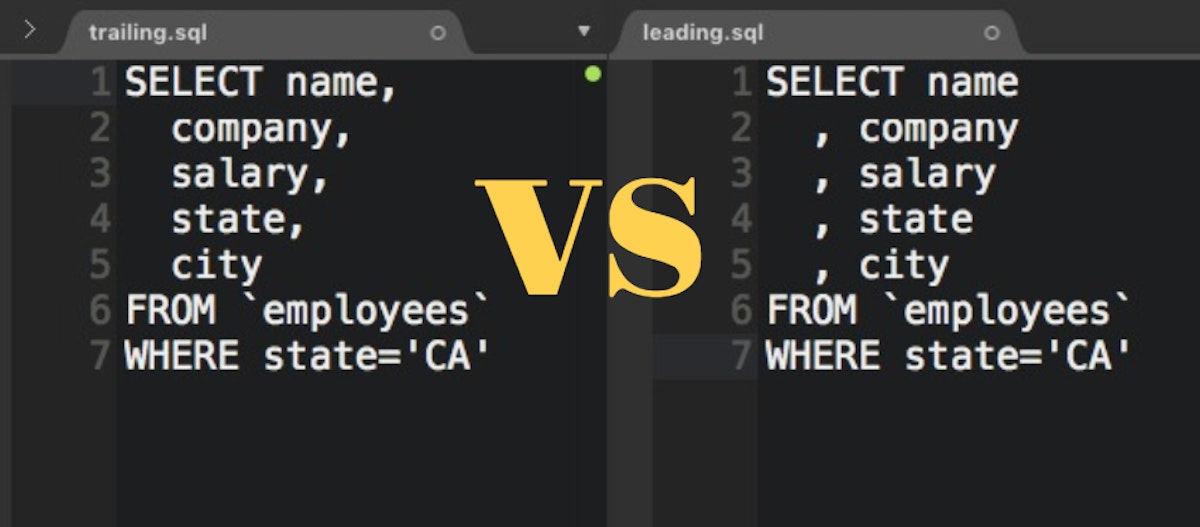
Winning arguments with data: Leading with commas in SQL?



Too Long; Didn't Read
Companies Mentioned




Felipe Hoffa
@hoffa
About Author


TOPICS
THIS ARTICLE WAS FEATURED IN...



RELATED STORIES






L O A D I N G
. . . comments & more!
. . . comments & more!
Share Your Thoughts